
随着财务数据量的增长,企业为了获得更好的报表功能和分析能力一直在努力简化数据管理。
在近期出版的《SAP Simple Finance软件概述》一书中,Lob财务和SAP创新中心负责人Jens Krüger博士向读者介绍了SAP Simple Finance的HANA驱动应用的内部原理,这种应用就是为简化财务操作而设计的。
本系列文章节选自第三章:消除冗余。文中对SAP Simple Finance背后的核心理念之一(消除冗余)做了深度解释。
无冗余系统的优势
如果数据在不同位置出现多余副本就是出现了数据冗余。例如,存在于数据库两个独立的表中,或者可以从数据库中已经保存的其它数据计算而得到。通常,所有你可以从系统其它数据源获取的数据都是冗余的。冗余数据有一个显著的问题摆在眼前,就是你需要维护其一致性。如果你修改了一处数据,那么你需要对数据库中其它副本应用相应修改,以保持其完整关系并避免异常。冗余数据是需要高度维护的数据,它们不能自己处理好同步的事。
软件工程师们很早就认识到了数据冗余的问题。在1970年,Edgar Codd建立了基本的关系模型,直到今天的许多数据库系统仍然在采用该模型。为了减少冗余,这类正常形式的常规技术是关系模型不可缺少的组成部分。
但是数据冗余仍然存在。我们可以区分数据库系统中四种不同类型的冗余,根据冗余数据与原始数据的关系进行区分。
物化视图
物化视图存储来自一个或者多个表数据的子集,形成一个新的更小一点的表。它把数据库视图(存储的数据库查询)结果物化存储下来,为了提供对查询结果更直接的访问。因此,物化视图可以比作其基础表的索引。查询也可以连接多个表。
物化聚合
如果说物化视图查询需要聚合多个基础表,那么我们说物化聚合是一种特殊情况。物化聚合并不保留一对一的复制,但是尽管如此,数据仍然是冗余的,因为这些数据可以在任何时候从原始数据获得,只需在内存中进行相同运算即可。
(译注:物化聚合指的是把需要查询统计的数据提前计算出来并存储,查询请求时直接提取计算好的结果。也可以成为物化统计数据。后文统一简称为“物化聚合”)
原始数据重复
如果相关信息存储在不同的位置,那么数据有可能重复。有一部分数据是属性重叠,而其它部分只需要在一个地方出现。这种重叠是来源层面的冗余。需要不同的位置通常是因为关注点不一样,有时候重叠是因为性能原因,例如为了避免传统数据库系统关联查询的性能下降问题。
物化结果集
长时间运行的程序在多个计算步骤之后产生的输出结果往往会先作为物化结果集存储起来。由于程序逻辑的复杂性,该结果并不能描述某个查询,而是由程序生成的,存储这些数据只是为了未来更快速地引用和进一步计算。
所有这些冗余情况,从应用功能的角度来看没有一个是必要的。在过去这些年,它们都被引入到企业系统中来帮助提高查询响应速度,因为基于磁盘的数据库系统速度比较慢,而选择内存计算代价又比较昂贵。现在内存技术已经清除了性能障碍,因此SAPSimple Finance软件可以消除所有类型的冗余。本文介绍的内容涵盖了前两种类型的冗余消除,也就是物化视图和物化聚合。
如果你使用一个以上的数据库,在多个数据库系统之间复制相同数据或者派生数据时也会产生冗余。相比于单一数据库内部的冗余,这种跨系统复制可能在某些情况下是必要的。例如,为了数据安全而冗余。在另外一些情况下,却是真正的冗余。例如,在数据仓库中,由于传统数据库的分析处理能力不足,必须要冗余以提高性能。正如我们在第二章中提到的,系统级别的这种数据冗余天生就是多余的,因为SAP HANA整合了olTP(联机事务处理)和olAP(联机分析处理)两者的功能并获得了卓越的性能。
我们继续回到数据库内冗余的探讨,那么无冗余的系统到底有什么好处呢?在SAPSimple Finance软件中拥有单一数据来源比传统世界的物化视图有什么好处呢?毕竟物化视图是可以改善读操作性能的。
冗余数据的基本问题是:原始数据发生变化时必须努力保持冗余数据副本的一致性。如果你把某个客户的所有订单都物化一份副本,那么每次有该客户新订单进来时,你都要更新该副本。对那些更新频繁的数据做物化副本可能导致竞争,例如常用账户的余额,因为该账户每次存入和支出操作时都要锁定余额。
同理,物化视图包含有重复的账号数据子集(例如所有已开发票信息),不管什么时候,只要原始数据变了,就需要重新更新数据。如果开发票信息清除了,那么相应物化视图中的数据也要删除。
不管数据同步需要随着每次业务事务手工做,还是数据库自动处理,维护一致性会带来额外的数据库操作,这些都是实实在在的操作。否则的话,你的数据库数据就会有两份差异数据,不能保证一致性了。摆脱这种同步工作有以下几种益处:
简单原则:
总的来说,无冗余系统的架构和数据模型绝对会更简单。在修改或者分析数据时,事务需要考虑的依赖和限制会更少。因此,事务也更简单了。整体的简化还会带来其它一些好处。
设计保持一致性
修改数据的业务事务不需要为了维持一致性而作额外的工作。这会形成更简单的程序,因为数据模型不那么复杂,而且依赖更少。总的来说,无冗余系统的架构更自然:数据库中的事务记录是增加相应数据库记录时产生的。所有要提供的其它内容就是基于这些数据之上的只读算法。
增加吞吐量
由于并行模式下修改冗余数据不再是必须的,所以每个业务事务中执行的数据库操作数相应就减少了。只有必要的操作在记录事务发生的情况,没有必要留存额外的修改操作。每个事务的数据库操作更少了,因而其执行时间也更短了,增加了整个系统的吞吐量,因而可以处理更多业务事务。此外,物化聚合不再必须锁定更新操作,因此可以消除一些竞争问题。
数据库占用更少的资源
冗余数据占用内存和硬盘空间,在无冗余的系统中没有这个问题,这就缩小了整个数据库的资源消耗。更小的资源消耗不仅可以降低对主数据库服务器资源的需求,而且可以减少备份需求磁盘空间。较小的数据库资源占用和更高的吞吐量使得系统变得更加成本高效。最终,无冗余系统的总拥有成本(TCO)就更低。
实时灵活性
无冗余系统还意味着不再需要为改善性能而预构建聚合。更快的分析查询响应不再依赖于物化数据的可用性。查询不再受限制,可以直接基于设计系统数据模型时可预见的数据获得回答,用户提出的查询问题可以基于原始数据获得实时应答,这样非常灵活。内存中的无冗余系统提供了更高层次的灵活性,当今众多Web应用能快速响应正是基于此。
这些令人印象深刻的所有益处中有一个很明显的问题:为什么不是所有的系统都设计成无冗余的系统?还有,为什么SAP ERP财务系统以前没设计成这样的方式?
答案就是性能原因,因为过去的数据库都是基于传统磁盘技术的数据库系统。现在,在SAP HANA的世界里,我们已经没有保留冗余的理由了,这要多亏了如此高速的内存技术。以前的查询响应的时间太慢(尤其是涉及聚合统计的查询更慢),如果生产环境中没有采用物化处理,几乎是不可以忍受的。而当时设计无冗余系统的话代价太高,甚至要高过了其获得的益处。现在,更高级性能的内存数据库系统意味着对响应时间迟缓的畏惧已经成为了过去式,这一点在后面的文章中还会提到。下图描绘了相比于传统数据库,无冗余系统益处胜过成本的情况。
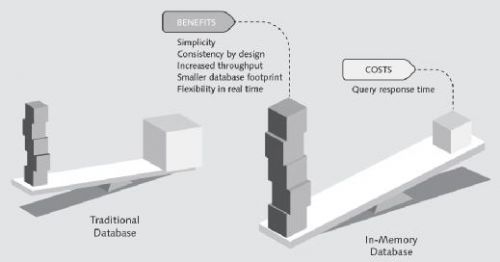
利用内存计算取代物化数据



